Critical Infrastructure Security: 10 Best Practices Every Facility Must Implement
 The Skylock Team
The Skylock Team

Critical infrastructure security usually breaks down at the point of verification. While most facilities are excellent at detecting activity, they struggle to confirm intent, leading to a flood of alarm noise, slow confirmation times, and delayed responses. To be effective, critical infrastructure security must be an integrated discipline. It is the unified protection of physical assets, cyber networks, OT/ICS systems, and the people and processes required to maintain operational continuity. When these layers operate in isolation, fragmentation doesn’t just confuse operators; it leads to inconsistent outcomes and avoidable operational hits.
The challenge is accelerating in our airspace. The FAA forecasts that the U.S. commercial small UAS fleet will reach approximately 1.11 million by 2029. This massive volume of legitimate low-altitude activity makes it easier for hostile actors to mask their intent behind routine flights. Without a process-driven approach to deter, detect, verify, respond, and recover, facility operators remain blind to the difference between a hobbyist and a threat.
Here are the 10 best practices to engineering your alarms for better verification and a 30–60–90 day plan to implement these standards across every shift.
What critical infrastructure security means today (and why point solutions fail)
Critical infrastructure security now covers the full chain of disruption, in addition to perimeter breaches. Facilities must contend with physical intrusion, insider threats, and cyberattacks. Vulnerabilities often emerge through supply chain exposure or OT/ICS disruptions, long before an on-site incident occurs. Low-altitude airspace now forms part of the perimeter. Drones can be used for surveillance, payload delivery, or to interfere with site operations.
The main problem is fragmentation, and it creates a predictable failure chain: siloed tools generate siloed alarms, which drives alert fatigue. Alert fatigue slows verification, and slow verification produces inconsistent response across shifts. The fix is not ‘more alerts’, it is clear ownership plus strict verification standards that hold under pressure. Use integrated command-and-control so every operator works from a single, accurate picture. Pair that with clear verification rules, then manage performance with three time-based metrics: time-to-detect, time-to-verify, and time-to-respond.
This model relies on integrated command-and-control and clear verification rules. Success is then maintained by monitoring time-based performance metrics for detection, verification, and response.
A simple operating model: Deter, Detect, Verify, Respond, Recover
Critical infrastructure security and exposure management work best when they run as a repeatable operating model, not as a collection of controls.
| Step | Purpose | What it looks like in practice |
| Deter | Reduce attempts | Visible protection, disciplined access control, clear consequences |
| Detect | Provide early warning | Coverage across physical, cyber, OT/ICS, supply chain indicators, and low-altitude airspace where relevant |
| Verify | Confirm what’s real | Correlate sources, apply confidence thresholds, cut false alarms, and prevent overreaction |
| Respond | Take authorised action | Defined actions with clear ownership, comms, and escalation paths |
| Recover | Restore and improve | Restore capability fast, capture lessons, improve readiness |
How the model maps to real facility ops
Visible protection only works if it is enforced. Detection requires multiple layers and regular health checks to be effective. You need a verification process that uses evidence from multiple sources to confirm a threat before authorising a response.
All actions taken during an incident must be rehearsed and aligned with your legal authority and site constraints. The recovery phase should focus on restoring services and improving future readiness through post-incident updates.
The 10 best practices every facility should implement
1. Run a threat-informed risk assessment (not just compliance)
Begin your assessment by identifying potential threat scenarios rather than jumping straight to security controls. For each scenario, score likelihood, impact, and time-to-impact, then identify the “critical timelines” that matter: how fast you need to detect, verify, and respond before the event becomes irreversible.
You need a ranked risk register, plus drone-scenario-based detection, verification, and response timelines for your top threats. Your risk register must detail specific scenarios such as sabotage, theft, protests, and insider threats. You should also account for cyber-physical attacks and drone incursions. Every entry must be ranked according to its probability, the severity of its impact, and the speed with which that impact occurs.
2. Define security zones and outcomes per zone
Effective security relies on defining zones based on the reality of escalation. Security includes the perimeter, inner rings, and restricted areas. You are required to specify the detection needs and verification standards for each location, along with a clear response owner. This process forces the organisation to reach consensus on what constitutes an acceptable delay for each zone. These parameters establish a necessary consensus between security teams and management on how quickly the facility must respond to an incident. This ensures that protection standards are consistent and agreed upon throughout the facility.
The best practice is to produce a zone map alongside a formal outcomes matrix that covers requirements, standards, and ownership. The framework assures that your team specifies how detection and verification function within each distinct zone. Setting a firm limit on acceptable delay is a requirement for measuring security effectiveness. These metrics serve as a clear standard for performance and help maintain accountability across all site operations.
3. Engineer verified alarms to reduce false positives
Do not rely on isolated alarms when correlation is possible. You must integrate inputs like OT alerts and network anomalies with operator confirmation to create an evidence-backed event. It is essential to define clear escalation paths and confidence levels to drive consistent decision-making during a crisis. Moving away from single-source triggers will lower your false alarm rate and prevent unnecessary call-outs.
Your perimeter requires alarm verification rules and escalation thresholds, including cross-cueing logic and confidence requirements. Don’t dispatch on single-source alerts when you can correlate. Build escalation rules: confidence thresholds, cross-cueing, and operator prompts to reduce nuisance alarms and speed decisions.
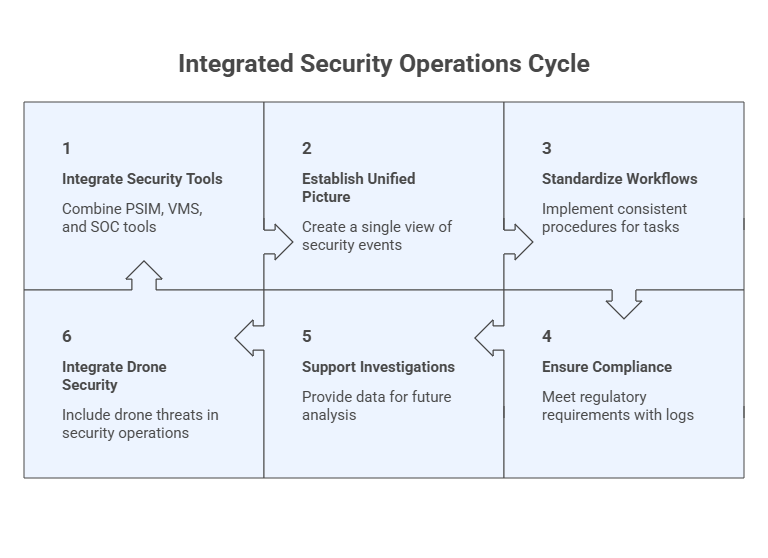
4. Make integration and command-and-control (C2) a requirement
Integration must be treated as a formal security control. Forcing operators to jump between different PSIM, VMS, and SOC tools slows down verification and causes response times to slip. You must establish requirements for a unified operating picture and standardised workflows. Essential features must include role-based access, comprehensive audit logs, and event timelines to ensure compliance and support future investigations.
This includes an integration requirements checklist (PSIM/VMS/SOC/C2) and a target event workflow that shows logging, roles, and end-to-end handoffs. Where drones and drone swarms are part of the threat picture, SKYLOCK is designed to integrate into existing command environments. Hence, airspace incidents follow the same verification, logging, and escalation discipline as other security events.
5. Build layered perimeter security with no single point of failure
Design your perimeter using layers of barriers, lighting, and detection technology. You are required to overlap these systems so that terrain and weather constraints do not create undetected gaps in your security. Your predetermined zone outcomes should drive all coverage. Your final security plan must prove where redundancy exists and include an honest assessment of blind spots and response speeds across the site.
Your perimeter strategy must combine physical barriers and lighting with active detection and patrols. Identify and document the blind spots in each zone, and demonstrate how the plan meets the required zone outcomes.
6. Harden access control for people, vehicles, and exceptions
Access control is most vulnerable during exceptions, so your strategy must address these gaps directly. You are required to formalise policies for identity proofing and least privilege, while ensuring the movement of visitors and contractors is secured through designated sponsors and strict escort rules. Vehicle checks at site gates must be engineered to remain effective during peak shift changes and busy delivery windows. A robust policy pack is essential to document these flows and ensure that entry requirements do not degrade under operational pressure.
All security exceptions require a defined continuity management process that is strictly limited in duration and fully auditable. You must move away from informal overrides and instead implement a system that requires a formal review for every deviation from standard policy.
7. Protect OT/ICS with segmentation, monitoring, and safe-state planning
Separating IT and OT environments is a fundamental requirement, but the focus must be on securing the bridges between them. You must implement secure remote access and allowlisting where feasible, alongside monitoring for anomalies that actually impact operational stability. It is vital to define a formal “safe state” for the facility and designate who possesses the authority to trigger it. This ensures that critical functions can continue even while an incident is being contained.
Protect your infrastructure with an OT segmentation and monitoring architecture plus a documented safe-state runbook (triggers, authority, steps, communications). Align to recovery requirements and continuity plans.
8. Design resilience into comms and power for security operations
Resilience requires identifying every sensor, C2 node, and network link vital to site operations. These critical components must be supported by verified backup power and continuous health monitoring. You are required to implement redundant communication paths and establish formal procedures for operating in degraded modes. Every system must have a manual fallback that personnel can execute without improvising during a crisis.
Your security needs a resilience plan covering backup power, comms redundancy, health monitoring, and a failover test schedule with pass/fail criteria. Backup power for critical sensors/C2; health monitoring; periodic failover tests.
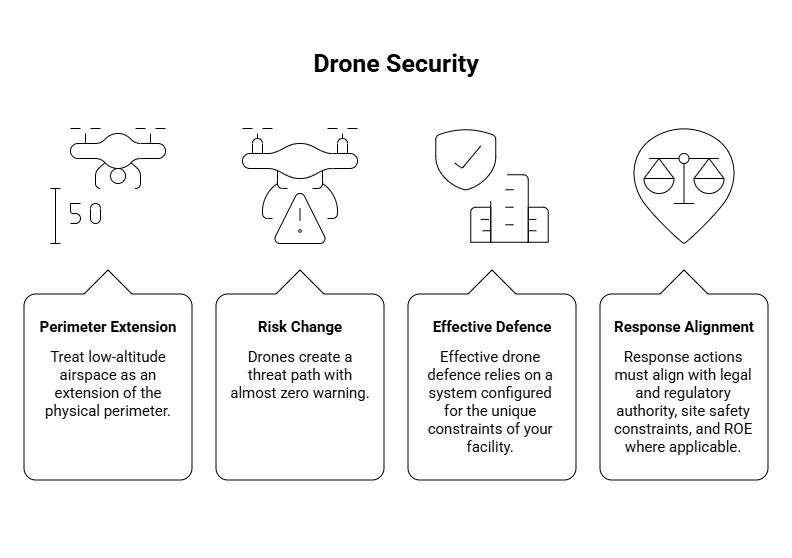
9. Treat low-altitude airspace as part of the perimeter
You must treat low-altitude airspace as an extension of the physical perimeter. This requires the same verify-first discipline and formal escalation paths used for ground-based threats. A drone incident is a perimeter event and demands immediate detection followed by rapid verification. You are required to establish a controlled response with designated ownership and detailed logging requirements. Integrating aerial threats into your existing security workflow ensures that response remains consistent regardless of the flight path.
Why drones change facility risk
Drones create a threat path with almost zero warning. They enable remote surveillance of patrol routes and sensitive areas without ever crossing the physical perimeter. You must account for the fact that these devices can deliver contraband with precision over fences and into restricted zones. Furthermore, repeated incursions can be used to disrupt operations or stage an attack by mapping out your response timings and identifying gaps in coverage.
What “good” drone security looks like
Effective drone defence relies on a system configured for the unique constraints of your facility. Factors such as site clutter and line-of-sight obstacles will dictate the success of your detection and classification sensors. You are required to calibrate your equipment based on the local environment rather than relying on generic factory configurations. This approach ensures the system is sensitive enough to detect small targets while remaining robust to environmental noise.
Response must align with authority and safety.
Response actions must align with legal and regulatory authority, site safety constraints, and ROE where applicable. That includes deconfliction planning, clear decision rights, and defined actions that don’t create new hazards or interfere with legitimate air activity.
SKYLOCK provides a layered counter-UAS capability that manages the detection, verification, and authorised neutralisation of aerial threats. The system is engineered to integrate with your existing command environment. This ensures that drone incursions are subject to the same escalation, logging, and response protocols as any other security event on site. By treating the airspace as a standard security workflow, you maintain a consistent and professional response to all unauthorised incursions.
10. Operationalise with drills, metrics, and sustainment
Effective security requires constant validation through practical training and drills. You should focus your training efforts on operational roles to ensure every team member understands their responsibilities during an escalation. Performance must be measured against clear benchmarks, including response times and system availability. Tracking the false alarm rate and verification speed lets you identify and fix technical bottlenecks before they affect a real-world incident.
30–60–90 day implementation plan
First 30 days: establish visibility and governance
You must first secure your fundamental operations by creating a scenario set based on actual disruption risks (physical, insider, cyber, OT/ICS, and drone risks where applicable). Rank scenarios by likelihood, impact, and time-to-impact, then convert them into shift-ready ownership and handover discipline.
Assign clear ownership by role and shift: designate a primary verifier, incident lead, OT/ICS liaison, and communications lead for every shift, with named backups and an escalation path.
Implement a standard shift handover checklist: open incidents and pending investigations; system health and degraded modes (sensors, networks, C2); active thresholds and verification rules; playbook or escalation changes since last shift; and any exceptions/temporary overrides currently in force.
In parallel, map your security zones from the perimeter to the most sensitive assets and define the specific detection and verification standards required for each.
60 days: integration and verified workflows
You must convert raw alerts into verified events by implementing formal alarm correlation rules and confidence thresholds. This ensures that operators are not required to piece together an incident manually. Before workflows go live, confirm response actions are aligned with legal authority, site safety constraints, and ROE where applicable.
Establish alarm verification rules and escalation thresholds (including explicit evidence requirements for dispatch and escalation), plus an integrated end-to-end event workflow that shows logging, roles, decision rights, shift-to-shift handoffs, and closure criteria, so incidents move from detection to verified response without ambiguity. You are required to integrate all priority feeds into a unified command-and-control environment to provide a single operating picture for the site.
90 days: exercise and baseline performance
A formal sustainment plan is required to maintain these performance standards over time. Run tabletop and live drills across all shifts to validate decision rights, handovers, and end-to-end response under realistic conditions, then baseline readiness metrics by shift, including time-to-detect, time-to-verify, time-to-respond, false alarm rate, and uptime/readiness.
Deliver a baseline performance report by shift that captures the metrics, key failure points, corrective actions, and named owners. In parallel, produce a sustainment pack that specifies the test schedule, patching and calibration cadence, spares list, vendor SLAs, and a formal acceptance test checklist for upgrades and repairs.
If You Cannot Verify Fast, You Cannot Protect Operations.
Critical infrastructure security holds up when it runs as an operating model: deter, detect, verify, respond, recover. That sequence forces discipline when the environment is noisy, and the stakes are high.
Building your security around verification ensures that system performance remains predictable. This approach eliminates nuisance alarms rather than forcing your teams to ignore them. You must quickly confirm the existence of a threat so that evidence rather than assumptions backs all response decisions. Clear ownership across shifts and stakeholders is achieved by formalising escalation paths and decision rights.
SKYLOCK fits into that model where drone risk is part of the perimeter, supporting detect–verify and, where authorised, neutralise, while integrating into existing command environments so drone incidents follow the same workflow discipline as any other security event. If you want to reduce false alarms and standardise verified response, talk to a SKYLOCK expert about integrating counter-UAS into your facility’s operating model.


